
Wearable health scores simplify complex biometric data into a single daily number, helping users make decisions about rest, activity, or recovery. However, their accuracy is often questionable due to limited validation, sensor inconsistencies, and opaque algorithms. Only 11% of wearables since 2003 have undergone proper validation, which raises concerns about their reliability for health decisions. These scores rely on metrics like HRV, resting heart rate, and sleep tracking, but issues like motion artifacts, gaps in data, and "double-dipping" errors can distort results.
Key takeaways:
- Accuracy issues: Many scores are based on flawed sensor data or proprietary "black-box" algorithms.
- Validation gaps: Few devices meet rigorous scientific standards for sleep accuracy, making their health insights less reliable.
- Improvement needs: Transparency, personal baselines, and uncertainty ranges could enhance score reliability.
Wearable scores are best for tracking long-term trends, not single-day health decisions. For meaningful improvements, better validation methods and clear data transparency are essential.
Wearable Health Score Metrics: Accuracy Tiers & Validation Gaps
How Wearable Health Scores Are Built
Key Metrics Used in Health Scores
At the heart of every health score lies a combination of biometric signals that work together to provide meaningful insights. The most commonly used inputs include heart rate variability (HRV), resting heart rate (RHR), sleep stages, and activity load.
| Metric | What It Measures | Typical Weight in Score |
|---|---|---|
| HRV (rMSSD) | Autonomic nervous system balance | High - often 35–60% [7][8] |
| Resting Heart Rate | Cardiovascular strain and recovery | Moderate - 20–40% [7][8] |
| Sleep Stages | Physical and mental repair | Moderate - 25–30% [7][8] |
| Activity Load | Cumulative cardiovascular stress | Low to moderate - 10–20% [2][8] |
| SpO2 | Blood oxygen saturation | Low - ~5% [7][8] |
Most wearable devices rely on PPG sensors combined with accelerometers to collect this data. Once gathered, the raw signals are normalized against a personal baseline, which usually takes 14 to 21 days of consistent use to establish [2][3]. Until this baseline is set, the scores you see are largely based on population averages rather than your unique physiology.
Interestingly, even small changes can be revealing. For example, an increase of just 3–5 bpm in your resting heart rate compared to your baseline might indicate fatigue or the onset of illness up to 48 hours before symptoms appear [7].
Once metrics are normalized, they’re fed into proprietary algorithms that calculate the final health score.
Proprietary Algorithms and Their Drawbacks
After the initial cleaning and normalization process, raw data is weighted and combined into a composite score, typically ranging from 0 to 100 [3][4]. However, the specifics of how these scores are calculated are not shared publicly.
"Vendor scores are proprietary black boxes. Oura, Whoop, and Garmin do not publish their scoring algorithms, do not disclose their reference populations, and do not expose the raw inputs their scores depend on." - Piotr Ratkowski, Head of Growth, Momentum [2]
Each wearable brand applies its own priorities in designing their algorithms. For example:
- WHOOP focuses heavily on HRV, with about 60% of its Recovery Score based on how your morning HRV compares to your baseline [9].
- Oura spreads its Readiness Score across seven metrics, including body temperature [9].
- Garmin's Body Battery is more geared toward promoting daily activity rather than tracking deep recovery [2].
This means a score of 75 on one device could reflect an entirely different state of readiness compared to a 75 on another. The lack of transparency makes it challenging to audit, replicate, or directly compare scores across brands. This opacity remains a major hurdle in validating wearable health scores.
sbb-itb-f5765c6
What Should You Really Track? The Truth About Wearables, Bloodwork & Health Data
Challenges in Validating Wearable Health Scores
When it comes to wearable health scores, ensuring their accuracy is no simple task. A range of obstacles, from technical shortcomings to real-world limitations, makes validation a complex process.
Technical Issues
One of the first hurdles is the inconsistency of data collected by consumer-grade sensors. Even if the algorithms behind these devices were completely transparent, the data they rely on is often flawed. For instance, PPG (photoplethysmography) sensors are highly sensitive to motion artifacts. Something as small as a loose strap or slight movements during sleep can introduce noise into the readings. On top of that, individual factors like skin tone can affect accuracy. Darker skin tones, for example, can absorb more light at wavelengths below 650 nm, which may lead to higher error rates in PPG measurements [3][6].
Device performance also varies significantly. Independent testing has shown notable differences between wearables. For example, the Oura Gen 4 achieved an almost perfect Concordance Correlation Coefficient (CCC) of 0.99 when compared to an ECG reference, while the Garmin Fenix 6 scored a lower 0.87 [3]. Even minor inaccuracies in the data these devices collect can snowball into larger errors when combined into a composite score.
Limitations in Everyday Use
Wearables face another layer of challenges in real-world settings - scenarios that controlled lab environments don't fully account for. Dead batteries, missed charging sessions, or syncing issues can leave gaps in the data. Many devices attempt to compensate for these gaps by either estimating the missing data or discarding it entirely, often without making users aware of the potential inaccuracies [3][10].
Another issue is how these devices interpret activity. For example, heavy physical exertion might negatively impact an AI recovery score, even if other metrics - like a steady resting heart rate - indicate sufficient recovery [1]. This kind of misinterpretation, along with the phenomenon of "double-dipping" (where the same data is penalized multiple times), further complicates the reliability of these scores.
Scientific Defensibility
The biggest challenge might be ensuring that these scores are backed by solid scientific evidence. While some scores may seem meaningful, their clinical accuracy often falls short. Take sleep tracking, for instance: even the most advanced consumer devices show a Cohen's kappa of around 0.53 when compared to clinical sleep studies, meaning they disagree with lab results nearly half the time [3]. Calorie estimates are even more problematic, with average error rates exceeding 30% in many cases, and some studies reporting errors as high as 155% when compared to metabolic carts [11].
These discrepancies highlight a major issue: many wearables prioritize user engagement over clinical accuracy. Without transparency around algorithms, reference groups, or validation methods, it's nearly impossible to independently verify or audit the scores [10]. This lack of clarity is concerning because users often rely on these numbers to adjust their workouts, sleep habits, or even how they respond to potential health issues - all based on data that might not be entirely reliable. This is why many are turning to integrated health AI apps that synthesize multiple data points for better context.
Methods for Validating Wearable Scores
Tackling the technical and practical challenges of wearable health scores calls for strong validation methods.
Validation Approaches
To address issues like proprietary algorithms and sensor inaccuracies, researchers rely on structured frameworks to validate wearable health scores. A leading standard in this space is the V3+ Framework, described in npj Digital Medicine as "foundational to the evaluation of sDHTs for technical, scientific, and clinical performance" [12]. This framework breaks validation into four key areas: Verification, Analytical Validation, Clinical Validation, and Usability Validation.
Analytical validation focuses on comparing a device's output to a reference standard. However, the rigor of these reference measures can vary. For instance, polysomnography (PSG) is the gold standard for sleep staging, while nasal pressure transducers are used for respiratory rate despite lacking universal benchmarks. Manual or self-reported references, on the other hand, can introduce subjectivity. Selecting a reliable reference is critical, as weaker references can artificially inflate a wearable score's accuracy. Statistical calibration also matters - a robust validation process compares data against an individual's personal baseline rather than population averages. For statistical analysis, Confirmatory Factor Analysis (CFA) is favored over simpler metrics like Pearson Correlation Coefficients [14].
Wellness vs. Clinical Validation
The validation requirements depend heavily on whether the scores are aimed at general wellness or clinical applications. Wellness-focused scores prioritize user engagement and behavior change , often utilizing AI nudges for better health habits, often relying on proprietary methods. In contrast, clinical metrics adhere to strict, peer-reviewed standards [10][12].
| Feature | Wellness-Focused Scores | Clinically Oriented Metrics |
|---|---|---|
| Primary Goal | Consumer engagement and behavior change | Clinical decision-making |
| Validation Standard | Often proprietary; usability-focused | V3+ Framework |
| Reference Measure | Often none or internal consistency | High-rigor references (e.g., PSG, ECG) |
| Baseline Method | Population averages | Personal baseline |
| Transparency | Proprietary "black box" algorithms | Peer-reviewed, auditable methodology |
"Vendor scores are marketing features optimized for consumer engagement, not clinical precision. They are not interoperable and should not be used as health metrics in a product where accuracy matters." [10]
This distinction highlights the need to tailor validation methods to the specific purpose of wearable health scores.
What the Evidence Shows About Wearable Scores
When it comes to wearable metrics, the evidence paints a mixed picture, highlighting both reliable measurements and areas where accuracy falls short.
Where the Evidence Holds Up
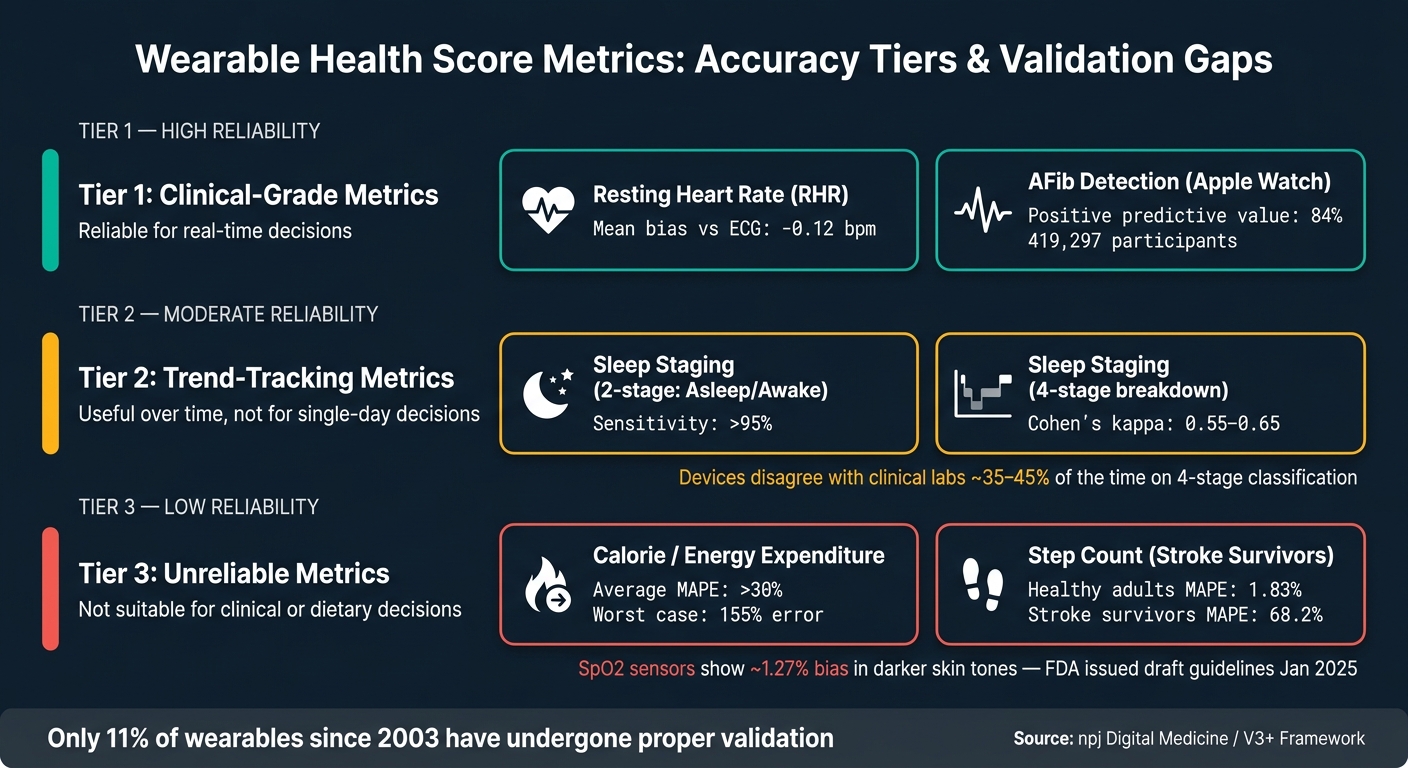
Wearable metrics are typically grouped into three tiers, and understanding these tiers can help gauge how much weight to give to each type of data.
Tier 1 metrics, like resting heart rate (RHR) and atrial fibrillation (AFib) detection, show the strongest reliability. For instance, the Apple Heart Study, which included 419,297 participants, found an 84% positive predictive value for irregular-pulse notifications [11]. Similarly, a 2025 meta-analysis of the Apple Watch showed a mean bias of just -0.12 bpm for RHR compared to ECG readings, which is negligible from a clinical perspective. This level of accuracy means these metrics can be used immediately for medical decisions without needing extensive historical data.
Tier 2 metrics, such as VO2max and sleep stages, are more suited for tracking trends over time. While they provide useful insights for improving sleep quality, they aren’t reliable enough for single-day readings to be treated as definitive. Take sleep staging as an example: consumer devices perform well (over 95% sensitivity) at distinguishing whether you're asleep or awake. However, when breaking sleep into four stages - Light, Deep, REM, and Wake - the accuracy drops, with a Cohen's kappa ranging from 0.55 to 0.65 [11]. This means these devices only moderately align with clinical standards for sleep classification.
In short, while some metrics are dependable enough for real-time clinical use, others are better suited for observing long-term trends.
Where Wearables Fall Short
Despite these strengths, certain metrics still struggle with accuracy. Energy expenditure, for instance, is the least reliable. Reviews consistently report calorie-tracking errors with a Mean Absolute Percentage Error (MAPE) exceeding 30%, and some studies show errors as high as 155% [11]. This makes wearable calorie counts unsuitable for clinical use or precise dietary planning.
Composite scores also face challenges in validation, especially across diverse populations. For example, step count accuracy is impressive for healthy adults, with a MAPE of just 1.83% for the Apple Watch. But for stroke survivors walking at slower speeds, the error rate jumps to 68.2% [11]. Similarly, SpO2 sensors show a bias of about 1.27 percentage points in individuals with darker skin tones [11]. This issue has drawn attention from regulators, prompting the FDA in January 2025 to issue draft guidelines requiring pulse oximeters to be tested across various skin tones using the Monk Skin Tone scale [11].
"A clinician who treats a wearable AFib alert the same way they treat a wearable calorie count is going to make bad calls in both directions - over-reacting to noise, and under-reacting to signal." - Centralive [11]
Ultimately, wearable scores are most effective when used to monitor changes over time for an individual. Relying on a single absolute reading to define health can lead to misleading conclusions.
How to Improve Validation for Wearable Health Scores
What Better Validation Requires
To improve validation, we need to move away from vendor-specific scores and adopt transparent, standardized methods. These should rely on device-agnostic, auditable raw signals. By addressing issues like data quality and transparency, we can create a stronger connection between raw sensor data and actionable insights. Metrics such as rMSSD, sleep stage durations, and resting heart rate are consistent across devices and can be independently verified - unlike vendor-created scores, which often prioritize user engagement over clinical reliability [10].
Another key step is calibrating score calculations using personal baselines and including explicit uncertainty ranges. For example, after a 14–21 day calibration period, scores should reflect individual baselines and display confidence intervals (e.g., "Readiness: 72 ± 8") to show the true reliability of the measurement [5][3]. Additionally, artifact detection should be implemented to filter out data corrupted by motion, reducing the risk of false alerts [3]. On days with unreliable data, scores should be suppressed, ideally targeting a suppression rate of 5–15% [3].
"A composite score is only as good as the confidence attached to it. If you can't see which inputs fed the number... you're trusting an opinion instead of a measurement." - Omnio Blog [3]
These changes not only improve the accuracy of health scores but also create a more dependable foundation for AI-driven health coaching.
Impact on AI-Powered Health Coaching
Better validation directly enhances the reliability of AI-powered health recommendations. By solving issues like sensor inaccuracies and misleading scoring, these improvements ensure that AI systems are built on solid data. As Piotr Ratkowski, Head of Growth at Momentum, explains:
"The AI layer built on an unreliable scoring foundation produces confident-sounding recommendations with no real grounding. This is worse than no AI layer because it adds apparent authority to uncertain information." [10]
When scores are based on normalized, well-calibrated data, AI systems can analyze structured health facts instead of noisy, raw time-series data. This is the difference between vague advice and actionable insights like, "Your recovery today is lower than your Tuesday average - consider a lighter workout." Apps like Healify use this approach to turn wearable data into clear, personalized action plans, rather than just presenting numbers without context. This context is essential when you create a personal health dashboard to track long-term progress.
Equally important are safeguards. AI systems should include constraints that prevent them from making medical diagnoses or offering overly confident recommendations when the underlying data is unreliable. In cases of low data confidence, AI should hold back recommendations, request more data, or flag uncertainties instead of making guesses [10].
| Validation Requirement | Impact on AI Coaching |
|---|---|
| Normalized raw signals | AI interprets consistent, device-agnostic information |
| Personal baselines (14–21 days) | Identifies subtle changes beyond population averages |
| Uncertainty intervals | Reduces overconfidence in noisy or incomplete data |
| Score suppression | Encourages AI to defer or seek more data when needed |
| Artifact detection | Avoids false alerts for fatigue or illness |
Conclusion
Wearable health scores hold potential but often face challenges in delivering reliable results. Issues like proprietary algorithms, lack of uncertainty ranges, dependence on population norms, and sensor noise undermine the credibility of these composite scores. As Jessie P. Bakker, PhD, of the Digital Medicine Society, aptly stated:
"The quality of the evidence reported for analytical validation of sDHTs... is inconsistent and too often insufficient to support a particular digital measure as fit-for-purpose." [13]
Currently, these devices are most effective for long-term trend tracking. They can reasonably capture directional changes over weeks or months but struggle with single-day accuracy. For instance, a 2026 audit using conformal prediction highlighted the potential of integrating meaningful uncertainty intervals, showing a heart rate mean absolute error (MAE) of just 0.046 bpm. However, such practices are far from being standard in the industry [5].
To improve reliability, validation practices need an overhaul. Key steps include using transparent raw-signal inputs, establishing personalized baselines over a period of 14–21 days, and incorporating confidence indicators to flag potentially unreliable scores. Without these foundational elements, AI systems cannot provide consistent or trustworthy insights. For platforms like Healify, which rely on AI-powered health coaching, rigorous validation is non-negotiable. Implementing these measures will ensure that wearable data translates into accurate, personalized, and dependable user guidance.
FAQs
How can I tell if my wearable score is actually validated?
Determining whether your wearable's health score is reliable can be tricky. Most brands use proprietary algorithms, and they rarely share details about the formulas or thresholds behind their calculations. While specific metrics, like heart rate or sleep duration, often have a basis in scientific research, how these numbers are blended into a single score is usually not supported by peer-reviewed studies or shown to accurately represent your overall health.
Which wearable metrics are reliable enough to act on today?
Composite health scores might seem useful, but they often fall short when it comes to clinical validation and transparency. For a clearer picture of your health, it’s better to focus on raw biometric data like nightly resting heart rate (RHR) and heart rate variability (HRV) - especially RMSSD, a reliable HRV metric rooted in well-established physiological science.
Healify takes the guesswork out of interpreting your wearable data. It transforms those numbers into an actionable plan, helping you tune into your body’s signals without depending on oversimplified, generic scores.
What should I do if my score drops but I feel fine?
If your wearable health score takes a dip but you’re feeling okay, don’t stress. These scores can be swayed by things like eating late, having a drink, traveling, or even a glitch with the sensor. Treat the score as just one piece of the puzzle. If it doesn’t align with how you feel, rely on your instincts and how your body feels instead. The score might be picking up on stress, tiredness, or other factors the algorithm can’t perfectly interpret.